Generating ``bullet-time'' effects of human free-viewpoint videos is critical for immersive visual effects and VR/AR experience. Recent neural advances still lack the controllable and interactive bullet-time design ability for human free-viewpoint rendering, especially under the real-time, dynamic and general setting for our trajectory-aware task. To fill this gap, in this paper we propose a neural interactive bullet-time generator (iButter) for photo-realistic human free-viewpoint rendering from dense RGB streams, which enables flexible and interactive design for human bullet-time visual effects. Our iButter approach consists of a real-time preview and design stage as well as a trajectory-aware refinement stage. During preview, we propose an interactive bullet-time design approach by extending the NeRF rendering to a real-time and dynamic setting and getting rid of the tedious per-scene training. To this end, our bullet-time design stage utilizes a hybrid training set, light-weight network design and an efficient silhouette-based sampling strategy. During refinement, we introduce an efficient trajectory-aware scheme within 20 minutes, which jointly encodes the spatial, temporal consistency and semantic cues along the designed trajectory, achieving photo-realistic bullet-time viewing experience of human activities. Extensive experiments demonstrate the effectiveness of our approach for convenient interactive bullet-time design and photo-realistic human free-viewpoint video generation.
System Architechture
Our neural interactive bullet-time generator (iButter) enables convenient, flexible and interactive design for human bullet-time visual effects from dense RGB streams, and achieves high-quality and photo-realistic human performance rendering along the designed trajectory.

Pipeline
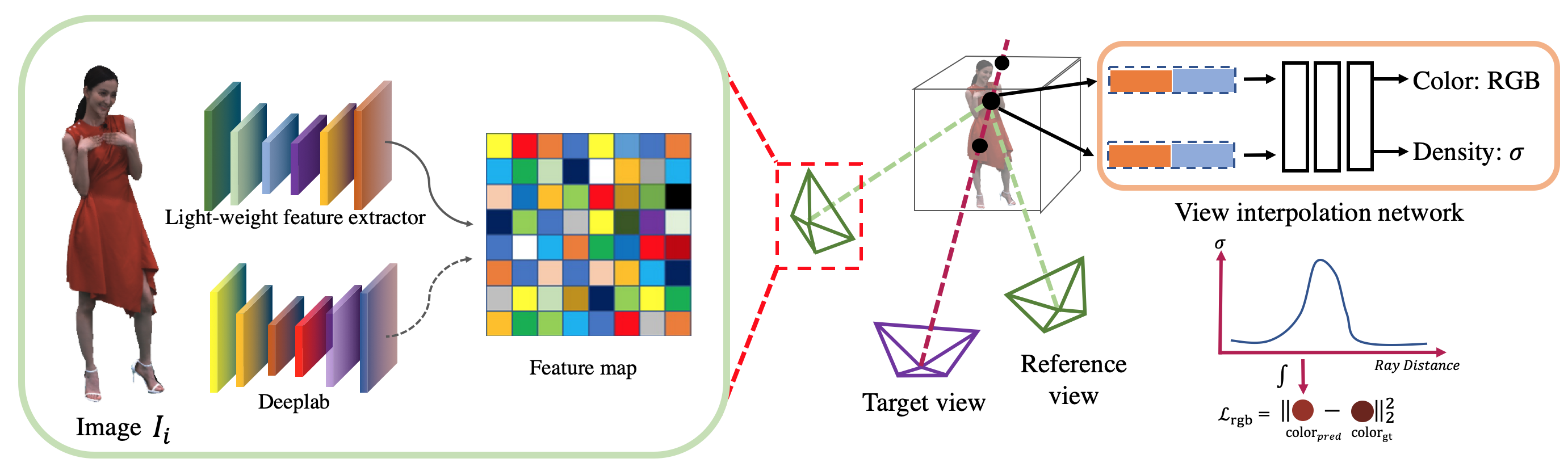
Our high quality rendering network enables realistic rendering without per-scene training. The whole architecture can be divided into three parts: feature extraction, view interpolating, and volume rendering.
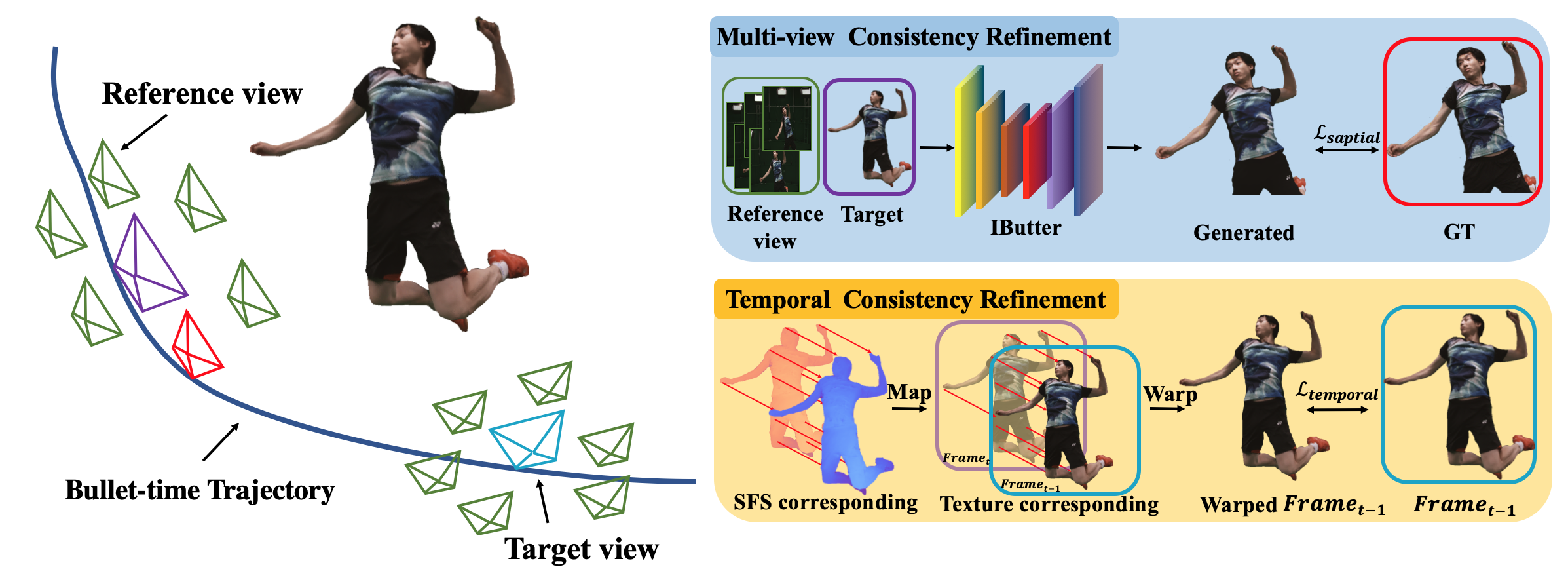
Our trajectory-aware refinement scheme applies both spatial consistency loss and temporal consistency loss to improve rendering quality.
Results

Several examples that demonstrate the quality and fidelity of the render results (right) from the trajectory user designed (left) from our system on the data we captured, including human portrait, human with objects and multi humans.
Bibtex
Minye and Xu, Lan and Yu, Jingyi}, title = {IButter: Neural Interactive Bullet Time Generator for Human Free-Viewpoint Rendering}, year = {2021}, isbn = {9781450386517}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3474085.3475412}, booktitle = {Proceedings of the 29th ACM International Conference on Multimedia}, pages = {4641–4650}, numpages = {10} }